Can We Fix the Broken Review Process of the ML Conferences?
Disclaimer: opinions are my own.
Machine Learning (ML) is like no other field in academia. The speed of development is insanely fast, and I think unless you are a robot, you can’t easily keep up with the pace of papers. Whether this is a good thing or not is for another day. Just to give you a hint, look at the number of submissions of top ML venus in recent years (source):
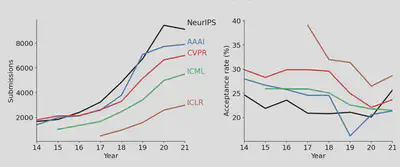
Consequently, because of this load, the quality of reviews drops. Also, the probability of getting bad reviews increases. You can watch this short video where Hinton is telling his experience. This happened at AAAI'20, the first conference I’ve ever attended!
The problem is not just the quality of the reviews. The acceptance rate going down, plus the field becoming more competitive, makes things harder. It’s become so hard to publish in top-tier venues that apparently, even Yann LeCun couldn’t get into ICML this year:
Verdict from @icmlconf:
— Yann LeCun (@ylecun) May 16, 2022
3 out of 3 ..... rejected.
If I go by tweet statistics, ICML has rejeted every single paper this year 🤣
My Experience On This Topic:
Since last year, I reviewed 6 papers for NeurIPS'21, 3 papers for ICLR'21, 3 papers for ICML'22, 4 papers for AISTATS'22, and 4 papers for AAAI'22! Being a student, I also understand the frustration of getting a low-quality review. Personally, I spend about 3 to 4 hours per paper and only review papers related to my thesis. While I’m still a junior reviewer, I believe I give fair and helpful reviews. Last year, I was selected among outstanding reviewers for NeurIPS'21.
As a PhD student, I have published (as a first author) in AAAI, IJCAI, ICML, NeurIPS, and ICLR. I also had papers rejected from ICML, AISTATS, and AAAI.
So, hopefully, I can see the story from both sides.
0 - The Madness
There are a couple of factors contributing to this trend:
Academia, just like the industry, moves wherever the money tells it to move. With more and more investment in ML, more people work on ML. Both industrial and academic labs. So the field is becoming more crowded and competitive.
Doing applied research on ML is becoming easier and easier. Most of the ML papers are empirical, with some theoretical sprinkles here and there. For these empirical works, all you have to do is to come up with a hypothesis, run an experiment, and if your results are interesting, write a paper about them. For that, you’ll need a good experimentation infrastructure, which is becoming easier and more accessible with those cheap and powerful GPU/TPUs and great libraries on top of powerful numerical frameworks.
Unlike journals, conferences have a very fast turnaround. Nature journal has a median of 226 days from submission to acceptance. For ML conferences, this is about ~120 days. I personally like this fast turnaround and cannot tolerate waiting for 8 months just to get a rejection! However, some people exploit this fast turnaround and submit a work that they know will be rejected just to get some free and quick feedback from at least 3 reviewers.
For some reason that is beyond my understanding, the number of publications in those top venues is a measure of academic success. People show off that they have N papers accepted to conference Y this year, and to get even an internship interview with top companies, you must have a few publications at these top conferences. This latter is a significant incentive for students, including yours truly.
Now, who has to deal with this crazy load of submissions? Conference organizers (reviewers, chairs, etc.)!
As I said before, I think the most common problem is the quality of reviews. We have a name for a bad reviewer: Reviewer #2!
](/post/ml-conferences/r2-memes_hu6d0bb76a3139473040b49a269d2e2bb7_541640_d8f243f8aff536393295df74047d3a86.webp)
But jokes aside, it’s so frustrating to see a short and unfair review after spending months of your time on a paper. I remember once I started my Ph.D., I was working on Knowledge Distillation for model optimization. By luck, I found an interesting limitation of the knowledge distillation and proposed a simple fix for it. I worked really, really hard on that project. I was staying in the lab up to 4 and 5 in the morning. I didn’t take a single day of break for two months, including the Christmas breaks! I didn’t work because I had to. I was really passionate and excited about what I had found and wanted to work more. We submitted the paper to ICML'19. It got rejected! I’ll never forget the day I saw the reviews for that (first) paper of mine!
I really couldn’t believe it. The problem (knowledge distillation) was important, the idea was novel, and the results were good. What else could I have done? Why did they reject the paper? When I was discussing the decision with my mentor, and he was like:

Fun fact, we later resubmitted the paper to AAAI and that paper has 355 citations as of today! By no means I’m claiming that’s a groundbreaking paper. But it was certainly an impactful paper, in my opinion.
The story shows how noisy the reviewer process can be. If you look at Twitter or Reddit, you’ll find several stories like this. I just told you mine. Now, what have we done, and what can we do about this madness?
1- History: What Have We Done?
Well, let’s talk about some ideas and discuss their merits and flaws. Program Chairs, being aware of these problems, have tried creative ideas with no luck so far:
Pruning the submissions
NeurIPS'20 introduced desk-rejection for the first time in top-tier ML conferences. The idea of desk rejection is simple and common for journals: Not every submission has to be reviewed. Area chairs, as experts, will quickly check the paper to see if it’s good enough to be reviewed.
What happened then? Let’s take a look at this official NeurIPS blog post.
Based on the results of the NeurIPS 2020 experiment that showed that roughly 6% of desk-rejected submissions would have been accepted if they had gone through the full review process and the amount of time that area chairs devoted to desk rejections, we decided not to continue desk rejections this year. Papers may still be rejected without review if they violate the page limit or other submission requirements.
That’s not an awful number. But, given that they have ~10000 submissions, with a ~10% desk-rejection rate, it means that ~60 papers could have been accepted but desk-rejected. Well, if we assume it took ~4 months of work for each paper, which is not a crazy number, in total, it would be ~20 years of academic work that we are talking about. However, I think the real numbers (if we could have calculated the total number of unfair decisions across all ML conferences) are much higher. Also, this is an inefficient process. ACS spent days/weeks on this process.
Well, not surprisingly, this experiment failed with lots of heated discussions.
Later, AAAI and ICML tweaked the desk-rejection idea into something called two-phase review. In phase 1, a paper will be reviewed by two reviewers. If both of them reject the paper, it goes to a meta-reviewer, and if the meta-reviewer also rejects the paper, the paper will be rejected. If any of those 3 accept the paper, the paper goes for phase 2, which is a normal review phase.
Now, this has some merits. First, it’s not very harsh. You have to get 3 rejects to be rejected. Second, it’s faster because the reviews of phase 1 could be used for phase 2, and you don’t need to use ACs. It’s also easier for reviewers. Their workload will be divided into two parts. They review ~2 papers for phase 1 and then ~2 papers for phase 2 (instead of 4 papers at once). The problem I saw this year at ICML was that some phase 1 reviewers became disengaged after phase 1. But still, I think this is a running experiment, and we have to wait and see.
I think the main problem with the pruning technique is that, at best, it’s not efficient, and at worst, it’s unfair. They do all these things only to reduce the workload by 10%. However, the total number of submissions is too high, and this reduction is not solving the main problem. Also, the rate of submission grows faster than this pruning rate. So either they have to prune more, which will bring even more controversy, or they have to give up!
I honestly don’t have a better alternative. I think a funnel-like approach would be the best way if we want to prune. This is how recommender systems work! The idea of a two-phase review is like the idea of a two-stage recommender system! But the problem is, if your recommender system doesn’t work, the user will not be hurt. But if your review process doesn’t work, you are literally wasting months of time and energy of many people.
Reducing the bias: no visible scores for authors/reviewers
This is the most absurd idea I have ever seen!
ICML'22 introduced a tweak: reviewers recommendations in phase 2 are not visible to meta-reviewers; the meta-reviewers will decide based on the reviews. Here’s what happened this year at ICML:
Expectation Reviewers give their review regarding various factors (e.g., novelty, contributions, etc.). They will also make a decision, but no one will see that decision except the chairs and the reviewer. The meta-reviewer makes a decision based on comments and not the scores. So the meta reviewer has to read all the reviews carefully and decide based on factual comments and not a number.
Reality Some reviewers explicitly mention their decisions at the end of their long reviews. Maybe it was a force of habit. But I saw this happened at least once for 4 papers that I reviewed and 3 papers I submitted! Even worse, during the discussion period, the meta-reviewer comes and asks something like “should we accept this paper or not?”, “This is a borderline paper. Can we reach a consensus?”. Then the other reviewers came and explicitly mentioned “I think this paper should be accepted/rejected because …”. Then the question is, what’s the point of hiding the scores?
Overall, I think this didn’t work at all. I like the idea of making everyone talk objectively based on factual arguments. But I don’t think this way of implementation works.
2- My Proposals
Now I have a few proposals that may or may not work! Regardless, I think we really need to sit and talk about our publication process and come up with a good and scalable solution.
Proposal 0: Let’s talk about it! All of us!
I think we are not working on this problem enough! At the end of every conference, everyone complains for a while on Twitter or Reddit. We forget until the next conference comes.
Organizers try to come up with some solutions by themselves, but I think this process should be more rigorous and more inclusive:
Why don't we have a democratic way of managing conferences? It seems program chairs every year decide to make some arbitrary changes (with good intentions) without asking opinions of authors/reviewers/area chairs, etc. It just doesn't feel right. A thread 👇
— Soheil Feizi (@FeiziSoheil) April 15, 2022
Why not have a long session at the end of each conference with authors, reviewers, organizers, etc.? I think conferences should add a special track where people can propose a solution that can make the conferences better. For this track, the reviewers should be authors, other reviewers, and organizers. Each paper can have 10s of reviews, and the top-N papers will be awarded during the conference. The good ideas could be implemented next year. Why not?
Proposal 1: Collect more data about the reviewing process.
NeurIPS is doing a great job on this topic. I think other conferences should also do this. I also think there should be more data collected so we can understand the problems better.
Let’s look at an interesting consistency experiment by NeurIPS: Basically, they randomly selected ~10% of the submissions (~882 papers) as duplicate papers and reviewed them twice with different area chairs and different reviewers. Here’s what happened:
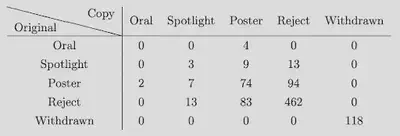
More than half of all spotlights recommended by either committee were rejected by the other!
23% of the papers had inconsistent decisions between those two groups.
While this shows how noisy our review cycle is, I really appreciate the effort by NeurIPS organizers. I think we need more experiments like this to understand the problems better. Hopefully, it can lead to better solutions!
Proposal 2: Making the review format more rigorous
It really hurts when a reviewer comes and says something like “The work is not novel”, and then they reject the paper. We should make it harder for an unprofessional reviewer to get away with these kinds of comments. I don’t think it’s fair to give a vague and non constructive feedback!
Why can’t we change the review form to have more detailed fields? For instance, let’s talk about novelty. What if, instead of a text box, we had something like this:
(1) Is the problem novel?: e.g., Yes/No/NA
(2) Is the proposed method novel?: e.g., Yes/No/NA
(3) support: If you think the work is not novel, why? (required if selected No): e.g., mention some previous similar works.
There are many other things that I think reviewers should provide. For instance, for common reasons for rejection, we should ask the reviewers to support their claims:
Results are not significant –> what constitutes a significant result in the context of this work? Are all results are non-significant, or part of the results is not significant?
The paper is not well written –> Which part(s) of the paper was confusing? What are the suggestions for improvement?
Experiments are poor / claims are not supported –> List the claims that you think are not supported.
I think if, instead of 4 or 5 text boxes, we had 20 text boxes which detailed instructions, it would be harder for reviewers to get away with low-quality reviews. It will be easier for the meta-reviewers to discard the bad review as well. Also, it will be easier to talk about facts during the rebuttal/discussion periods rather than abstract and vague argument. Finally, if the paper gets rejected, at least the authors have some helpful feedback to work with.
Proposal 3: Holding the reviewers responsible for their reviews and providing better incentives for high-quality reviews.
I think one problem is that the reviewers are not accountable even if they provide bad reviews, probably because they work for free! They also have zero incentive for providing a good review, apart from a thank you letter and a row they can add to their CVs for being an outstanding reviewer. I think this has to change. Why should a reviewer who gives low-quality reviews be able to review again? Why shouldn’t we evaluate the reviewers?
Here are a couple of suggestions:
There should be a mandatory feedback, provided by the authors. For each conference, each reviewer usually reviews at least 3 papers. Suppose 2 or 3 of those feedback forms complain about the reviewer. In that case, I think AC/SAC/PCs should read the paper, reviews, authors’ feedback form and then decide if the claim by the authors is correct. If ACs decide the reviewer provides a low-quality review, they should not invite that reviewer for the following year.
Companies, universities, and organizers should provide better incentives for outstanding reviewers. At the very least, I think there should be a fund for outstanding reviewers which will be virtually nothing if all conference sponsors contribute. Imagine if a student knew they could get ~2k if they are being selected as an outstanding reviewer for NeurIPS! This is not a small amount for a student at all. Big companies and universities can also award their employees who have been selected as outstanding reviewers. If many universities/companies participate in this program, I think the quality of reviews can improve significantly.
There could be another form of incentive. If someone is selected as an outstanding reviewer a few times (e.g., 3 times), they’ll get a free submission at the conference, and they can present their work without the review hustle. Some conferences are doing this when they invite someone to be a program chair, and I think it may work.
Conclusion
Currently, the review process of big ML conferences is very noisy. One reason is that there is a crazy number of submissions as ML becomes more and more popular.
I proposed a few candidate solutions today that may or may not work. But I think as a community, we really need to sit down and stop this madness. Let’s discuss these issues, and come up with some reasonable solutions. It’s a tough task, but I think we can do it!
Update
5/27/2022: After writing this post, I saw a thread on Twitter about The Future of Reviewing in ACL. There were couple of similar suggestions to this post such as evaluating/incentivizing the reviewers.