Abstract
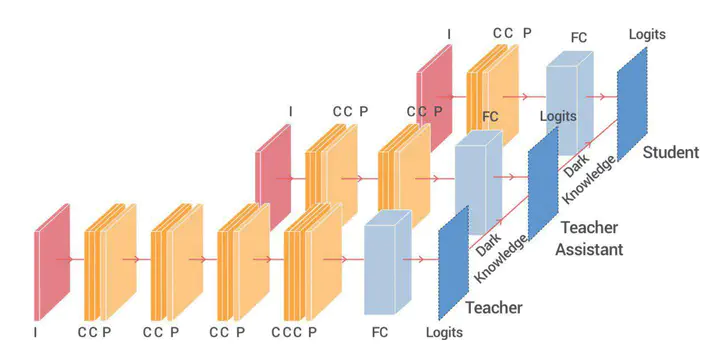
Despite the fact that deep neural networks are powerful models and achieve appealing results on many tasks, they are too gigantic to be deployed on edge devices like smart-phones or embedded sensor nodes. There has been efforts to compress these networks, and a popular method is knowledge distillation, where a large (teacher) pre-trained network is used to train a smaller ( student) network. However, in this paper, we show that the student network performance degrades when the gap between student and teacher is large. Given a fixed student network, one cannot employ an arbitrarily large teacher, or in other words, a teacher can effectively transfer its knowledge to students up to a certain size, not smaller. To alleviate this shortcoming, we introduce multi-step knowledge distillation which employs an intermediate-sized network (teacher assistant) to bridge the gap between the student and the teacher. Moreover, we study the effect of teacher assistant size and extend the framework to multi-step distillation. Theoretical analysis and extensive experiments on CIFAR-10, CIFAR-100 and ImageNet datasets and on CNN and ResNet architectures substantiate the effectiveness of our proposed approach.